Может для sequence лучше назвать “новый” метод просто .ToString вместо .JoinToString – так было бы и гораздо короче и единообразнее.
Нет, .ToString уже определено и делает другое. Join явно говорит что это соединение элементов последовательности.

И насчёт реализации .Indeces - есть несколько вещей которые можно улучшить:
PrefixFunction:
ArrFill(n + 1, 0)
Лучше:
new integer[n+1]
Массив в .Net всегда заполняется нулями при инициализации. Вот только .Net использует более эффективный метод для этого - заполняя всю область за одну операцию, вместо кучи маленьких заполнений.
Кроме того, вы же никогда не используете Result[0], зачем +1 элемент массива?
IndicesOf:
L.Select(i -> i - 1).ToArray
Я вроде уже несколько раз говорил, .Select.ToArray это убийца производительности.
Result := new integer[L.Count];
// если уберёте смещение индексов - можно будет так (что ещё и быстрее):
//L.CopyTo(Result);
// ну а в данном случае:
for var i := 0 to Result.Length-1 do
Result[i] := l[i]-1;
А ещё вы неаккуратно скопипастили EachCount:
/// Возвращает словарь, сопоставляющий ключу группы результат групповой операции
function Each<T,T1,Res>(Self: sequence of System.Linq.IGrouping<T,Res>; grOperation: System.Linq.IGrouping<T,Res> -> T1): Dictionary<T,integer>; extensionmethod;
begin
Result := Self.ToDictionary(g -> g.Key, g -> g.Count);
end;
Селектор нигде не применяется. И возвращается Dictionary<T,integer>. Да и шаблонным параметрам лучше дать более осмысленные имена:
/// Возвращает словарь, сопоставляющий ключу группы результат групповой операции
function Each<TKey,TValue,TRes>(Self: sequence of System.Linq.IGrouping<TKey,TValue>; grOperation: System.Linq.IGrouping<TKey,TValue> -> TRes): Dictionary<TKey,TRes>; extensionmethod;
begin
Result := Self.ToDictionary(g -> g.Key, grOperation);
end;
Дурная практика - надеяться на это. Сегодня заполняется, а как завтра будет, особенно в .NET Core если - кто его знает. Алгоритм, зависящий от особенности реализации системы (в данном случае - зануление) - это пусть враги пишут. Заранее обеспечивать непереносимость на другую платформу ради нескольких миллисекунд - это забава для школьников и студентов, а серьезные люди так не пишут.
Видите ли, там алгоритм надо очень тщательно и аккуратно ковырять, потому что он написан был для массива с индексацией от 1. Ну не стоит ковыряние в этом алгоритме одного сэкономленного элемента внутреннего массива.
Возможно, если использовать многократно и на длинном массиве. Но тут массив практически всегда небольшой, так что пусть лучше пока будет нагляднее, чем на миллисекунду быстрее.
-
Это задокументировано:
https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/arrays/single-dimensional-arrays
-
Если управляемая память и стек в .Net перестанут инициализироваться нулями - .Net перестанет быть .Net . Такого рода безопасность это один из основных принципов .Net .
А ожидать поведения старых паскалей и других низкоуровневых языков как
C- не лучше чем писать в стиле старых паскалей, под предлогом типа “лямбды могут падать, лучше не буду их использовать”.
Наглядность в подпрограмме, на реализацию которой никто кроме особо интересующихся вроде меня не посмотрит - это излишнее. А вот производительность в такой подпрограмме важна, потому что если IndicesOf где то понадобиться - это вряд ли будет один вызов.
Еще раз: я не буду привязывать библиотечный алгоритм к особенностям среды исполнения. Все инициализации должны быть явными (видны в коде) - это азы программирования.
Там хватает других тормозов, так что этот - наименьшее из зол.
А, да, спасибо, исправлю - это мы пробуем под VS Code компилятор сделать
Исправил, спасибо
Нет, SunSerega прав - new в NET всегда заполняет память нулями. Хоть где.
RAlex, надеемся, что вы скоро перепишете без n+1 и Select.ToArray 
3 лайка
@Admin только что обнаружилось - в последней версии кодировка ввода сломана:
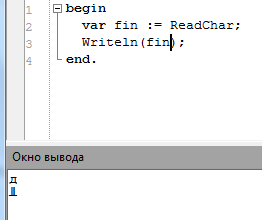
begin
var fin := ReadChar;
Writeln(fin);
end.
Это именно проблема ввода а не вывода, если проверять на равенство строке с русской буквой - всегда даёт False.
А, да, читаю Соколиного глаза с его извечными ссылками на volvo ))
Спасибо. Исправили. Версия на сайте.
Налицо прогресс Соколиного глаза. Раньше он призывал переходить всех на C#, теперь, спустя полтора года, на Free Pascal ))
3 лайка
Тогда уж регресс. C# - все же язык новее, современнее, да и мощнее.
А за пределами .NET? Вспомнит ли кто-то через год-другой, что надо массив занулять обязательно, перенося функцию за пределы .NET ? Что до единички этой - мы же так и договаривались, эта версия функции не окончательная, она лишь чтобы не тормозить с выходом сборки.
Ну, сборка вышла - надо оптимизировать )) Оно и так конечно этот алгоритм оптимальнее любого другого, но надо его вылизать )
Я писал, что там алгоритм не совсем тривиальный, он использует значения некоторых элементов в качестве индексов. Уже несколько раз пытался поменять - вроде начинал работать, а потом находился вариант, когда работал неверно. Поэтому не хочу вгорячах влепить глючное.
А вообще, теперь я нормально закопался в алгоритм (то есть посмотрел не_поверхностно):
function PrefixFunction(s: string): array of integer;
// возвращает массив граней для строки-аргумента
begin
var n := s.Length;
Result := ArrFill(n + 1, 0);
for var i := 1 to n - 1 do
begin
var temp := Result[i];
while (temp > 0) and (s[i + 1] <> s[temp + 1]) do
temp := Result[temp];
Result[i + 1] := s[i + 1] = s[temp + 1] ? temp + 1 : 0
end
end;
Когда выполниться условие temp > 0 ?
P.S. А, разобрался с КМП алгоритмом, теперь это понятнее. Это просто костыль для первой итерации.
Окончательно разобрался с КМП и написал это:
///Возвращает массив индексов вхождений подстроки в основную строку
///Использует алгоритм КМП
///Параметр allow_overlap определяет, разрешены ли перекрытия вхождений подстрок
function IndicesOf1(self: sequence of char; value: string; allow_overlap: boolean): sequence of integer; extensionmethod;
begin
{$region prefix inds}
var val_inds := new integer[value.Length];
// val_inds[0] никогда не заполняется и остаётся нулём
// Примеры заполнения:
// value : abcab
// знач. i : 01234
// val_inds: 0012
// value : aabaabaaa
// знач. i : 012345678
// val_inds: 10123452
var prev_val_ind := 0;
for var i := 1 to value.Length-1 do
begin
while true do
begin
if value[prev_val_ind + 1] = value[i + 1] then
begin
prev_val_ind += 1;
break;
end;
if prev_val_ind=0 then break;
prev_val_ind := val_inds[prev_val_ind-1];
end;
val_inds[i] := prev_val_ind;
end;
{$endregion prefix inds}
{$region Result}
prev_val_ind := 0;
var res_ind := -(value.Length-1);
foreach var ch in self do
begin
while true do
begin
if value[prev_val_ind + 1] = ch then
begin
prev_val_ind += 1;
break;
end;
if prev_val_ind=0 then break;
prev_val_ind := val_inds[prev_val_ind-1];
end;
if prev_val_ind=value.Length then
begin
yield res_ind;
prev_val_ind := allow_overlap ? val_inds[prev_val_ind-1] : 0;
end;
res_ind += 1;
end;
{$endregion Result}
end;
///Возвращает массив индексов вхождений подстроки в основную строку
///Использует алгоритм КМП
///Перекрытия вхождений подстрок запрещены
function IndicesOf1(self: sequence of char; value: string): sequence of integer; extensionmethod := self.IndicesOf1(value,false);
Почему последовательности
Список индексов результата вообще не нужен алгоритму, потому что он поточный.
Я так понимаю, в коде @RAlex он был только потому, что тот код переведён из старых кодов, где последовательностей вообще не было.
Ну а я не переводил, а писал новый код, как умел.
И задокументировал, что принимает какие значения.
Поэтому с моим кодом такого не будет:
Кроме проведения полной отладки поиска префиксов - я так же провёл эти тесты:
begin
'abcabcabcab'.IndicesOf1('abcab', true).Println;
// 0 3 6
//пересекающиеся вхождение находит
'abcababcab'.IndicesOf1('abcab', false).Println;
// 0 5
//подряд идущие вхождения находит
end.
Другие тесты пока не могу придумать. Потому что алгоритм поиска прификсов это и есть алгоритм поиска вхождений строки, а значит большинство вещей уже протестировано и отлажено.
P.S. Вообще этот же алгоритм прекрасно работает и с value: IList<T> с любым T, но string не реализует IList<char>. Поэтому если и расширять область применение дальше строк - то уже отдельной перегрузкой.
 Институт математики, механики и компьютерных наук ЮФУ, 2005–2021
Институт математики, механики и компьютерных наук ЮФУ, 2005–2021