Возможно Вы не все ветки смотрели, но вопросы оптимизации уже поднимались и по ним вроде как уже все ясно. Ниша PascalАВС.NЕТ - это обучение. На 90-95% это так. И разработчики вопросами оптимизации заниматься в ближайшее время точно не станут по одной простой причине: некому и некогда. Если и вторая: а надо ли? Гораздо более важных проблем - выше крыши, как говорится.
@Алекс, вы немного не поняли: оптимизация самого кода на Паскале, чтобы студент мог выявить “узкие места”, оценить ситуацию и понять в сторону чего копать и что менять – прямо по теме обучения. Неплохо бы иметь доступ к статистике; другое дело, если это значительно усложнит оболочку или понимание…
@Сергей, внешний профилировщик ресурсов для исполняемого файла вместо обычного счётчика вызовов скорее похоже на стрельбу из пушки по воробьям) Хотя вы правы - я подумал, что не разобрался где смотреть или какие директивы компилятора, а иначе только через внутренний подсчёт, так что надо обмозговать.
Кстати, об оптимизации "на скорость"
Недавно узнал, что школьный учитель требует заменять все пользовательские функции процедурами, потому что после вычисления функции обратно копируют результат, замедляя работу… Зачем там супер-скорость? Это где так же учат или испорченный телефон в действии? Хотя одиннадцать медалей по информатике забрали именно русские
Вообще, я когда то читал на хабре как создавать дебагеры… И вроде в WinAPI обязательно придётся залезть, но в целом не сильно сложно. Если не хотите готовые программы написать - можете попробовать сделать чтото. Может даже на паскале и опубликовать потом тут))
Скорее всего, школьный учитель ничего не слышал про инлайн-функции. В любом случае, это может верно для какой-то конкретной реализации конкретного языка, не более.
function Evens(n: integer) :=
SeqRandom(10 * n, 2, 98).Where(t -> t.IsEven).Take(n).ToArray;
procedure Evens(n: integer; var a:array of integer);
begin
a:=SeqRandom(10 * n, 2, 98).Where(t -> t.IsEven).Take(n).ToArray;
end;
begin
var t: integer;
var a:array of integer;
var k := 100000;
Milliseconds;
loop k do
a := Evens(50);
t := MillisecondsDelta;
Println(t * 1000 / k, 'мс');
Milliseconds;
loop k do
Evens(50,a);
t := MillisecondsDelta;
Println(t * 1000 / k, 'мс')
end.
Надо будет написать про нишу нам как то яснее. Если используется в научных расчетах, то это никак не обучение.
Обучение сразу ассоциируется с глубокими школьниками, а это в зависимости от фантазии читающего это ассоциируется с программами с одним циклом. Поэтому 90 процентов обучениеиэто ерунда.
Несколько ранее, в теме "Ниша PascalABC.NЕТ:
Давайте как-то все же определимся насчет того, ерунда это, или нет.
Всё отличие в особенностях уровней обучения: _начальный-средний-продвинутый-учитель-разработчик:
Если на начальном и начально-среднем главное лишь бы хоть как-то работало, то на уверенном среднем и выше уже важно как именно работает и что оптимальнее.
Например, есть цикл на N итераций, а количество вызовов внутренней процедуры/функции, строки IF или переменной почему-то не совпадает; возникает вопрос: а что вызывает наибольшую нагрузку и куда что девается или вызывает/изменяет значения? Далее, часто кажется, будто самое простое решение – напрямую, забывая о вариантах и
нюансах
Ещё в школе учили, что x^n=x^(n/2)*x^(n/2) при чётной степени и x^n=x^([n-1]/2)*x^([n-1]/2)*x при нечётной, но меня удивляло, почему линейный подход с перемножением медленнее рекурсии вида
function WeissPower(X: LongInt; N: Word): LongInt;
var i: Integer;
begin
if N = 0 then WeissPower := 1
else
if N = 1 then WeissPower := X
else
if Odd(N) then
WeissPower := WeissPower(X * X, N div 2) * X { нечет }
else
WeissPower := WeissPower(X * X, N div 2) { чёт }
end {WeissPower};
В общем, это уже более осознанный подход, когда студент не просто подсчитал, что пешеход якобы двигался 35,3м/с, но и понимает суть, осознавая возможную несуразицу
Но к Паскалю это имеет примерно такое же отношение, как морская свинка к морю и свиньям. Оптимален в первую очередь должен быть алгоритм. Ведь язык программирования - это не более, чем средство донести алгоритм до компьютера и дать [компьютеру] этот алгоритм исполнить. Другое дело, что хорош тот язык, средства которого позволяют записывать алгоритм по-разному, быть может, как то влияя на эту самую оптимизацию (почему, в частности, мне и не нравится, к примеру, Python). Но выбирать языковые средства с той или иной целью (минимум трудозатрат, наибольшая степень наглядности, минимальное время выполнения и т.д.) - это и есть наиболее высокая, я бы даже сказал, профессиональная степень владения конкретным языком. Её есть смысл оттачивать только если человек собирается делать конкретный язык одним из основных своих инструментов.
Потому что линейный подход при возведении в степень, равную 2^k, потребует 2^k-1 умножение, а то, что представлено у Вас рекурсией - лишь немногим более k умножений, Это известное представление показателя степени в двоичной системе счисления. Но опять же, это алгоритм, а не реализация в том или ином языке. И тут можно свободно заменить рекурсию итерацией, скорее всего, получив еще больший выигрыш во времени.
1 лайк
Одно – делать по примеру или на основе скопипастенного, а совсем другое – осознанно выбирать и аргументировать наиболее подходящие решения. Разумеется, всё познаётся в сравнении, однако сложно что-то улучшать, даже не зная где может быть проблема (“бутылочное горлышко”). Вот как сравнить несколько вариантов, только догадываясь о том, что же забирает львиную долю ЦП/времени?
А для чистоты самого кода программы, мне видится решение в (1) отдельном модуле, (2) настройках директив (текстовый отчёт/файл после компиляции) или же действительно – (3) как внешняя утилита.
Нет предела совершенству) Почему-то в девятом-десятом классе более короткая и прямолинейная функция воспринималась проще и казалась, что должна быть быстрее разветвлённой рекурсии. Хотя только с опытом приходит понимание, но прогресс можно оценить даже статистически
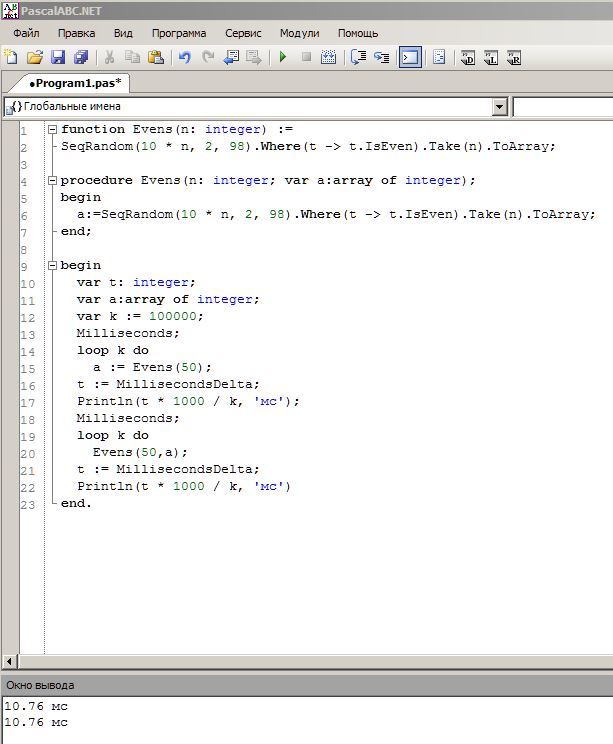
Есть примеры таймирования на основе Milliseconds / MillisecondsDelta. Собственно, вот тут я этим и воспользовался
ИМО
Однако такой тайминг работает кусками и
- не учитывает распределение кода программы по нагрузке/строкам/переменным;
- не может указать точные критические места; и
- искажает исходный код.
Возможно, это не самое актуальное и не для всех (как и собственно Паскаль), но мне бы точно пригодился функционал по оценке кода
Нет, просто вы неправильно используете.
Само их существование - ничего не делает с производительностью.
Нет, не искажает, потому что юнит-тесты надо делать.
Да, с таким подходом вам самому придётся искать где именно медленное место.
Но как я и сказал, надо мониторить всё и сразу - ищите или пишите программу которая работает для C#, для паскаля тоже сработает.
Но ожидать что это случится в ближайшем будущем не приходится, ибо некому.
1 лайк
Для .NET есть внешние профилировщики насколько я помню.
1 лайк
Ну, я примерно про такое и говорил, но не знал как это называется…
@NRA вот первое дефолтное от микрософта:
Но наверняка найдётся что-нибудь более качественное на гитхабе.
P.S. Мда, такое впечатление что этот стандартный профайлер делал школьник, даже окна не настроены нормально))) (ну то есть даёт менять размер, так что контролы не помещаются…)

А значит обязательно кто то уже сделал что то получше.
2 лайка
Подскажите пожалуйста. Как сделать учет, склад и соединить это с считывателей QR или штрих кодов? Есть ли готовые примеры? Что нужно: например: пробирка - штук на складе, штук выдано, цена такая-то, возможно несколько фото пробирки. при скармливании программе штрих кода или qr > штук на складе-1 выдано+1.
С чего начать? в чем хранить? как взаимодействовать с внешними устройствами?
Возможно такое вообще сделать?
Хранить скорее всего в словаре, с ключами - записями (хранящими QR код и кастомными операторами сравнения на равенство и методом получения хеш-кода), и значениями - классами хранящими информацию о кол-ве и о самом товаре.
Есть ли формула вроде RNG или способ через Seq/Where получить случайную уникальную последовательность, допустим, от 0 до 100 без повторений и без вспомогательного буфера (в данном случае, на 101 элемент)? Или хоть подскажите, что искать.
Благодарю
Буфер всё равно понадобится, разумеется, потому что надо сравнивать с предыдущими. Но можно чтоб это был внутренний буфер функции:
begin
SeqWhile(Random, o->Random, o->true)
.Select(r->r)//умножение, сложение чтоб получить нужную область чисел
.Distinct
.Take(10)
.Print
end.
В Distinct что то вроде:
var prev := new HashSet<T>;
foreach var curr in self do
if prev.add(curr) then
yield curr;
1 лайк
Я так делаю
begin
var m := 20;
var a := SeqRandom(1000 * m, 0, 100)
.Distinct.Take(m).ToArray;
a.Println;
end.
В счетчике там все равно что ставить, хотя бы на пару порядков больше m )))
1 лайк
 Институт математики, механики и компьютерных наук ЮФУ, 2005–2021
Институт математики, механики и компьютерных наук ЮФУ, 2005–2021