В тему последней лекции — свежая ссылка на Хабр: Рекуррентное соотношение Мюллера — специально подобранная простая формула, на которой быстро ломаются числа с плавающей точкой IEEE 754.
Если лень читать комментарии и ссылки из текста статьи, то краткое резюме такое:
вычисления с плавающей точкой могут давать сильно неправильные результаты даже на несложных соотношениях и небольших числах,
часто проблемы возникают при делении «похожих» чисел,
хотя многие общие проблемы понятны, но общих решений нет, в каждом конкретном случае нужно искать источник проблем, но, что ещё важнее, вначале надо заметить, что проблема вообще есть, для этого
следует понимать математическую структуру решаемой задачи, а не просто «запрограммировать формулы»,
хотя универсальных решений нет, есть несколько полезных трюков (вроде алгоритма Кэхана), которые следует знать, потому что они могут сильно облегчить жизнь.
Нет, именно процессором, у меня тоже так (хотя авторы с Хабра наверняка не слушали мой курс :)): числовые типы данных считаются частью уровня набора инструкций процессора. У конкретных процессоров могут присутствовать или нет инструкции для обработки этих данных в соответствующем представлении, а представления бывают разными. Так что конкретное представление связано именно с процессором.
Не согласен. Есть процессоры (например R600), которые работают с регистрами общего назначения и не отличают вещественные числа от целых. При этом набор бит в регистре воспринимается одними инструкциями как представление целого числа, а другими как вещественного. Я бы сказал, что процессор знает как обрабатывать набор бит. А что этот набор бит представляет, зависит не от процессора. Опять же набор бит - это ячейка(и) памяти, пусть и регистровой. Но это мнение человека, который не преподает курс по архитектурам.
Рома, ты будешь смеяться, но ты как раз подтвердил то, что это зависит от процессора, а не от памяти — раз можно хранить в регистрах общего назначения. Поясню. То, что интерпретация содержимого памяти (регистра или ОЗУ) зависит от исполняемой инструкции и говорит, что всё зависит от процессора, так как набор инструкций это артекфакт процессора, а не памяти.
И да, бит это не ячейка памяти. Бит это binary digit, двоичная цифра или двоичный разряд. Напомню, что слово разряд появляется в младшей школе при обучении счёту задолго до всяких компьютеров (во всяком случае, в наше с тобой время было так).
Когда вчера ложился спать, именно об этом и подумал: инструкция - это составляющая ФУ, а ФУ - это составляющая процессора. Согласен, что это был аргумент в пользу твоей точки зрения, а у меня в голове просто что-то заклинило.
Но утром я проснулся с другой мыслью. А как же быть с софтверной эмуляцией? Например, процессор может вообще не владеть плавучкой, но с помощью софт-флоат библиотеки можно проэмулировать ее. Тогда плавучка совсем не зависит от процессора.
И я понял, что меня скорее смущает не слово “процессор” в той фразе, а слово “представляет” по отношению к процессору. Процессор может интерпретировать, если у него есть такие инструкции, но не представлять.
Рома, я постепенно перестаю понимать твои аргументы
Насчёт софтверных эмуляций: они существуют у чего-угодно. Например, для квантового компьютера есть эмуляции: это не делает квантовые компьютеры областью памяти. Стандарт IEEE 754 разрабатывался для аппаратной реализации и на сегодня в подавляющем большинстве его поддерживают процессоры общего назначения (в микроконтроллерах часто используется фиксированная точка ввиду дороговизны плавающей). Софтверная его эмуляция вещь достаточно бессмысленная: чаще встречаются библиотечные реализации рациональных чисел с произвольной точностью (GNU MP и т. п.), а не вот эти 32-64-80 бит из стандарта: эти размеры затачивались именно под регистры.
Как именно процессоры поддерживают этот стандарт, с помощью микропрограммы или специализированных логических схем, это внутреннее дело процессора. Раньше (60-е и 70-е) даже инструкции умножения могли делать с помощью микропрограммного цикла, хотя схемную реализацию множителя можно объяснить даже студенту второго курса.
Насчёт того представляет или интерпретирует процессор инструкции и операнды это чистая риторика. Напомню, что процессор не только читает (наиболее близкое русское слово к «интерпретирует») инструкции и операнды из памяти, но и пишет (слово, которое можно считать упрощённым аналогом «представляет)» туда результаты.
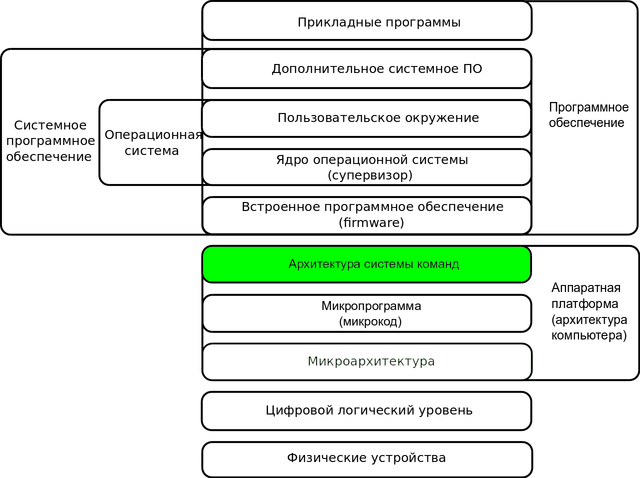
В конце хочу пожелать тебе всё-таки пройти по ссылке, которую я приводил выше, и почитать про архитектуру набора инструкций (ISA), хотя бы посмотреть на схему:
Потому что наивные соображения это всегда хорошо, но системный взгляд на вещи полезней. Наборы инструкций и «родные» для процессора типы операндов для этих инструкций считаются частью его интерфейса (то есть ISA) и с памятью никак не связаны.
Артем, ну я сразу пошел по ссылке, как только ты ее указал. И все же твой последний пост апелирует к моему первому утверждению про память, а уже признал, что был не прав.
Смысл последнего поста был в том, что мне не нравится сочетание “процессор представляет вещественные числа”. И я по прежнему считаю его некорректным, в частности потому, что иногда у процессора вообще нет команд работающих с вещественными числами, а значит он об их существовании и не знает.
Это правда, бывает, что не знает. Но если кто-то и знает и обрабатывает, то обычно процессор (бывают ещё FPU, правда), потому если писать про обработку, то, мне кажется, вполне нормальным говорить от имени процессора
Еще 1 вопрос, сервис БРС будет заполнен в самом конце? Было бы не плохо посмотреть текущее состояние и оценивать свои силы на предстоящей контрольной!!!


 Потому что наивные соображения это всегда хорошо, но системный взгляд на вещи полезней. Наборы инструкций и «родные» для процессора типы операндов для этих инструкций считаются частью его интерфейса (то есть ISA) и с памятью никак не связаны.
Потому что наивные соображения это всегда хорошо, но системный взгляд на вещи полезней. Наборы инструкций и «родные» для процессора типы операндов для этих инструкций считаются частью его интерфейса (то есть ISA) и с памятью никак не связаны.

 Институт математики, механики и компьютерных наук ЮФУ, 2005–2021
Институт математики, механики и компьютерных наук ЮФУ, 2005–2021