Проверьте свой код на вот этой задаче
Публичный пример проходит нормально. Для остального просит зарегистрироваться.
P.S. Всё же зарегестрировался:
Но вообще задача не на 100% показывает возможности моего решения. Если бы было разрешено вводить сначала искомую строку - можно было бы всё потоково искать:
SeqGen(1,i->ReadChar).Cycle
.TakeWhile(ch->ch<>#10)
.IndicesOf1(ReadString) // прочитает до начала вычисления последовательности
.PrintLines;
Там достаточно суровые тесты есть, раз прошло - значит работоспособная функция, можно больше тестов не искать. То, что все работает на последовательности - вполне понятно, КМП-алгоритм однопроходный. Вот только плохо, что он у Вас вдвое дольше работает при практически таких же затратах памяти.
Ну правильно, как я и сказал - в том тесте строка, в которой ищут, находится в начале ввода, поэтому в любом случае приходиться всё заранее прочитать.
В итоге в моём коде память экономиться только на выводе, потому что у меня не создаётся куча лишних массивов в списке, и затем в .Select.ToArray .
Ну а насчёт сколько экономится - я не вижу чтоб там было сказано, для строк какой длины отображает расход памяти. Да и сомневаюсь что их тестер умеет вставлять System.GC.Collect в код, чтоб смотреть не на кол-во мёртвых объектов в куче, а на реальных расход памяти.
Насчёт скорости - в ближайшее время проверю со стопвочем.
1 лайк
А Вы что, верите, будто вызов GC мгновенно освобождает память? Когда пользователь программу запускает, ему дела до GC нет никакого, это проблема системы - мусор убирать. Программирование всегда работает на результат, т.е. на общее время, которое уходит от запуска программы до получения результата. Также и расход памяти (если он интересен) интересен не в какой-то вымороченный момент и не функцию, а на программу в целом. Расход памяти и время на АСМР выдается для каждого прогона программы. И всегда можно посмотреть, как шло выполнение.
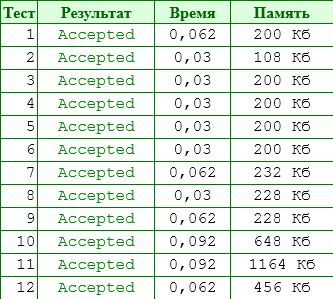
И не надо рассказывать, что если для Вашего решения создать какие-то особые условия, вот тут оно себя покажет. Решение должно нормально работать в любом случае, если уж Вы за него беретесь. А пока, извините, это все “я тут написал круто и оптимально, работает в потоке (нафига, спрашивается, нужна эта работа в потоке?), нет массива с лишним одним (!) элементом, да вообще - круть, как ни глянь” - оно программирование ради программирования, а не на результат. Получите на своем решении схожие значения - будет повод поговорить.
Это хорошие результаты - и по времени и по памяти. Сравнимые с Free Pascal. Зная, как меряется время на олимпиадных сайтах для .NET-приложений, - это отличный результат.
@Sun_Serega - если сможете переписать и улучшить алгоритм - будет круто. Но потоковостью с моей точки зрения не надо увлекаться - она может замедлить. Массив - он самый быстрый.
Не могу сейчас найти…
Ну, смысл прост: при запуске программы - запускаются 2 стопвоча. При каждом вызове Milliseconds и MillisecondsDelta - второй стопвоч обнуляется. Далее Milliseconds берёт время первого стопвоча, а MillisecondsDelta - второго. Больше, вроде, ничего не надо.
Да. Вызов System.GC.Collect замораживает вызвавший поток на пару сотен миллисекунд. Наверное же он там что то делает в это время. Без вызова System.GC.Collect - да, ничего сразу освобождаться не должно. И поэтому насиловать CLR вызовами сборщика - обычно плохая идея.
Моё решение работает нормально. Я говорю что при вводе строки в которой ищут в конце - можно читать потоково, на чём съэкономится ещё больше памяти. То есть тест который привели вы - по ТЗ не разрешает применить часть оптимизаций, которые уже были встроены.
Да, я потихоньку тестирую что можно сделать… Но то что могу сразу сказать - если заменить в моём коде yield на заполнение списка - для больших строк всё становится раза в 2 медленнее. Потоковость это не всегда плохо.
Но, что я так же нашёл - foreach по строке это жесть как медленно. Без него я уже смог получить результаты примерно как у @RAlex. Но факт что при результате в виде yield должно быть быстрее - значит что можно найти ещё что то улучшаемое.
А теперь я это не могу воспроизвести…
Ну, результаты лучше чему RAlex получаются без проблем:
program prog;
{$region RAlex 0}
function PrefixFunction0(s: string): array of integer;
// возвращает массив граней для строки-аргумента
begin
var n := s.Length;
Result := ArrFill(n + 1, 0);
for var i := 1 to n - 1 do
begin
var temp := Result[i];
while (temp > 0) and (s[i + 1] <> s[temp + 1]) do
temp := Result[temp];
Result[i + 1] := s[i + 1] = s[temp + 1] ? temp + 1 : 0
end
end;
/// Возвращает массив индексов вхождений подстроки в основную строку
///Параметр overlay определяет, разрешены ли перекрытия вхождений подстрок
function IndicesOf0(Self, SubS: string; overlay: boolean := False): array of integer; extensionmethod;
// Реализует КМП-алгоритм.
// Возвращает массив начальных позиций вхождений подстроки P в строку
// Параметр overlay определяет, разрешены ли перекрытия положений подстрок.
begin
var L := new List<integer>;
var (n, m) := (Self.Length, SubS.Length);
var border := PrefixFunction0(SubS);
var temp := 0;
for var i := 1 to n do
begin
while (temp > 0) and (SubS[temp + 1] <> Self[i]) do
temp := border[temp];
if SubS[temp + 1] = Self[i] then
temp += 1;
if temp = m then
begin
var pos := i - m + 1;
if overlay or (L.Count = 0) or (pos >= L[L.Count - 1] + m) then
L.Add(pos);
temp := border[m]
end;
end;
Result := L.Select(i -> i - 1).ToArray
end;
{$endregion RAlex 0}
{$region Sun Serega 1}
///Возвращает массив индексов вхождений подстроки в основную строку
///Использует алгоритм КМП
///Параметр allow_overlap определяет, разрешены ли перекрытия вхождений подстрок
function IndicesOf1(self, value: string; allow_overlap: boolean): List<integer>; extensionmethod;
begin
{$region prefix inds}
var val_inds := new integer[value.Length];
// val_inds[0] никогда не заполняется и остаётся нулём
// Примеры заполнения:
// value : abcab
// знач. i : 01234
// val_inds: 0012
// value : aabaabaaa
// знач. i : 012345678
// val_inds: 10123452
var prev_val_ind := 0;
for var i := 1 to value.Length-1 do
begin
while true do
begin
if value[prev_val_ind + 1] = value[i + 1] then
begin
prev_val_ind += 1;
break;
end;
if prev_val_ind=0 then break;
prev_val_ind := val_inds[prev_val_ind-1];
end;
val_inds[i] := prev_val_ind;
end;
{$endregion prefix inds}
{$region Result}
prev_val_ind := 0;
var res_l := value.Length;
var res_ind := -(res_l-1);
// foreach var ch in self do
// begin
// var enmr := self.GetEnumerator;
// while enmr.MoveNext do
// begin
// var ch := enmr.Current;
var res := new List<integer>;
for var i := 1 to self.Length do
begin
while true do
begin
if value[prev_val_ind + 1] = self[i] then
begin
prev_val_ind += 1;
if prev_val_ind=res_l then
begin
res += res_ind;
// yield res_ind;
prev_val_ind := allow_overlap ? val_inds[prev_val_ind-1] : 0;
end;
break;
end;
if prev_val_ind=0 then break;
prev_val_ind := val_inds[prev_val_ind-1];
end;
res_ind += 1;
end;
Result := res;
{$endregion Result}
end;
{$endregion Sun Serega 1}
begin
var lc1 := 100;
var lc2 := 10;
Randomize(0);
var s := new string(ArrRandom(100000, integer('а'),integer('д')).ConvertAll(i->char(i)));
var val := new string(ArrRandom(5, integer('а'),integer('д')).ConvertAll(i->char(i)));
// проверка результатов
s.IndicesOf0(val, true).Sum.Println;
s.IndicesOf1(val, true).Sum.Println;
// s.IndicesOf2(val, true).Println;
// проверка скорости
var sw0 := new System.Diagnostics.Stopwatch;
var sw1 := new System.Diagnostics.Stopwatch;
var sw2 := new System.Diagnostics.Stopwatch;
for var i := 1 to lc1 do
begin
sw0.Start;
loop lc2 do foreach var res in s.IndicesOf0(val, true) do ;
sw0.Stop;
sw1.Start;
loop lc2 do foreach var res in s.IndicesOf1(val, true) do ;
sw1.Stop;
// sw2.Start;
// loop lc2 do foreach var res in s.IndicesOf2(val, true) do ;
// sw2.Stop;
System.Console.Title := (i/lc1).ToString('P');
end;
Writeln(sw0.Elapsed);
Writeln(sw1.Elapsed);
// Writeln(sw2.Elapsed);
Readln;
end.
Особенно если результатов много (как при val.Length=1) - у моего варианта преимущество вообще раза в полтора. Ну а при тех значениях что в коде выше - прирост небольшой.
Всё же, должно быть ещё что то что можно улучшить. Но я, почему то, не могу сосредоточится (такой чувство, как умудрился простыть не выходя из дома).
1 лайк
А можно такую же табличку с АСМР, как я приводил?
Ну и толку тогда в последовательности, если результат все равное обычно приходится хранить в массиве?
Не всегда. А когда нужно сохранить в списке - обычно ещё и с промежуточным преобразованием.
Последний пример когда мне на практике нужен был производительный поиск в строке - это когда я парсил .pdf файлы. Там надо было найти все вхождения определённых строк и начинать парсить с этих позиций.
Массив индексов был бы вообще ни к чему:
- Как и сказал - преобразование. В результате нужен не индекс, а экземпляр класса, содержащего пропарсенные данные.
- Не все результаты нужны. Большинство из них отбрасывалось.
- И результат тоже не нужен был в виде массива. Он как поточно парсился - так же поточно записывался в файл.
И объемы информации там были довольно большие, мне пришлось дополнительно упрощать и делать другие части поточными, потому что жрало слишком много оперативки.
Даже если бы я знал как - зачем? Результаты которые выдаёт тот сайт - не понятно откуда взяты. Для каких строк, как собранных, какой длины.
Я привёл тест, использующий StopWatch с его аппаратной поддержкой замеров времени. А так же возможностью видеть как создаются строки и удобно менять любые параметры.
Иными словами, массив “ни к чему” в некоторых частных случаях. А поиск только одного первого вхождения - он лучше и быстрее работает с регуляркой.
Тем не менее, они есть. И, как ни странно, они улучшаются, если решение оптимизируешь - это проверено на 100%. Тесты там злобные, некоторые такие, что и в страшном сне не приснятся. Я бы так сказал - экстремальные. И поэтому результат прогона программы там - это тоже показатель, как бы Вам не хотелось считать иначе.
А в каких применениях на практике нужен массив?
Регулярки? Быстрее? Это где такое видано?
Если б не улучшались - этот сайт вообще ничего не стоил бы. Но - представьте себе, со стопвочем тоже улучшается.
А суровость тестов может показать работоспособность алгоритма. Она не может адекватно применяться к проверкам производительности. Для проверок производительности надо вообще не одно число, а таблица значений, в зависимости от входных данных.
И вот мой тест позволяет построить такую таблицу. А тест приведённого вами сайта - нет.
Ну, ждём таблицу с тестами )) Я тоже считаю, что тесты должны быть не только с acmp
А, ну, я не имел в виду прям настоящую таблицу составлять, я говорил про сравнение в уме результатов с разными входными данными… Но, почему бы и нет:
program prog;
{$region RAlex 0}
function PrefixFunction0(s: string): array of integer;
// возвращает массив граней для строки-аргумента
begin
var n := s.Length;
Result := ArrFill(n + 1, 0);
for var i := 1 to n - 1 do
begin
var temp := Result[i];
while (temp > 0) and (s[i + 1] <> s[temp + 1]) do
temp := Result[temp];
Result[i + 1] := s[i + 1] = s[temp + 1] ? temp + 1 : 0
end
end;
/// Возвращает массив индексов вхождений подстроки в основную строку
///Параметр overlay определяет, разрешены ли перекрытия вхождений подстрок
function IndicesOf0(Self, SubS: string; overlay: boolean := False): array of integer; extensionmethod;
// Реализует КМП-алгоритм.
// Возвращает массив начальных позиций вхождений подстроки P в строку
// Параметр overlay определяет, разрешены ли перекрытия положений подстрок.
begin
var L := new List<integer>;
var (n, m) := (Self.Length, SubS.Length);
var border := PrefixFunction0(SubS);
var temp := 0;
for var i := 1 to n do
begin
while (temp > 0) and (SubS[temp + 1] <> Self[i]) do
temp := border[temp];
if SubS[temp + 1] = Self[i] then
temp += 1;
if temp = m then
begin
var pos := i - m + 1;
if overlay or (L.Count = 0) or (pos >= L[L.Count - 1] + m) then
L.Add(pos);
temp := border[m]
end;
end;
Result := L.Select(i -> i - 1).ToArray
end;
{$endregion RAlex 0}
{$region Sun Serega 1}
///Возвращает массив индексов вхождений подстроки в основную строку
///Использует алгоритм КМП
///Параметр allow_overlap определяет, разрешены ли перекрытия вхождений подстрок
function IndicesOf1(self, value: string; allow_overlap: boolean): List<integer>; extensionmethod;
begin
{$region prefix inds}
var val_inds := new integer[value.Length];
// val_inds[0] никогда не заполняется и остаётся нулём
// Примеры заполнения:
// value : abcab
// знач. i : 01234
// val_inds: 0012
// value : aabaabaaa
// знач. i : 012345678
// val_inds: 10123452
var prev_val_ind := 0;
for var i := 1 to value.Length-1 do
begin
while true do
begin
if value[prev_val_ind + 1] = value[i + 1] then
begin
prev_val_ind += 1;
break;
end;
if prev_val_ind=0 then break;
prev_val_ind := val_inds[prev_val_ind-1];
end;
val_inds[i] := prev_val_ind;
end;
{$endregion prefix inds}
{$region Result}
prev_val_ind := 0;
var res_l := value.Length;
var res := new List<integer>;
for var i := 1 to self.Length do
begin
while true do
begin
if value[prev_val_ind + 1] = self[i] then
begin
prev_val_ind += 1;
if prev_val_ind=res_l then
begin
res += i-res_l;
prev_val_ind := allow_overlap ? val_inds[prev_val_ind-1] : 0;
end;
break;
end;
if prev_val_ind=0 then break;
prev_val_ind := val_inds[prev_val_ind-1];
end;
end;
Result := res;
{$endregion Result}
end;
{$endregion Sun Serega 1}
procedure Otp(name: object; params ress: array of object);
begin
name.ToString.PadRight(2).Print;
foreach var res in ress do
res.ToString.PadRight(20).Print;
Println;
end;
begin
var lc1 := 100;
var lc2 := 10;
Randomize(0);
var s := new string(ArrRandom(100000, integer('а'),integer('д')).ConvertAll(i->char(i)));
Otp('','RAlex','','Sun Serega','');
Otp('аа','Да','Нет','Да','Нет');
for var l := 1 to 20 do
begin
var val1 := new string(ArrFill(l, 'а')); // строка из одинаковых символов
var val2 := new string(ArrGen(l, i->char(integer('а')+i))); // строка из всех разных символов
var sw01 := new System.Diagnostics.Stopwatch;
var sw02 := new System.Diagnostics.Stopwatch;
var sw11 := new System.Diagnostics.Stopwatch;
var sw12 := new System.Diagnostics.Stopwatch;
for var i := 1 to lc1 do
begin
sw01.Start;
loop lc2 do foreach var res in s.IndicesOf0(val1, true) do ;
sw01.Stop;
sw02.Start;
loop lc2 do foreach var res in s.IndicesOf0(val2, true) do ;
sw02.Stop;
sw11.Start;
loop lc2 do foreach var res in s.IndicesOf1(val1, true) do ;
sw11.Stop;
sw12.Start;
loop lc2 do foreach var res in s.IndicesOf1(val2, true) do ;
sw12.Stop;
System.Console.Title := (i/lc1).ToString('P');
end;
Otp(l, sw01.Elapsed,sw02.Elapsed, sw11.Elapsed,sw12.Elapsed);
end;
Readln;
end.
Ничего кроме разделения поисковой строки по длине и повторению символов - не придумал. Но, если что, добавить ещё что-нибудь - легко.
Ну и время каждого теста сократил в 10 раз, раз их теперь 20. И ещё подправил пару мелочей в своём коде.
Вот результаты у меня:
RAlex Sun Serega
аа Да Нет Да Нет
1 00:00:01.9446194 00:00:01.8666370 00:00:01.0706198 00:00:01.0684475
2 00:00:01.0356399 00:00:01.0638883 00:00:00.6895404 00:00:00.7234651
3 00:00:00.8871421 00:00:00.9394501 00:00:00.6257238 00:00:00.6759779
4 00:00:00.8581729 00:00:00.9057806 00:00:00.6200921 00:00:00.6624243
5 00:00:00.8516302 00:00:00.8926988 00:00:00.6143702 00:00:00.6578825
6 00:00:00.8460627 00:00:00.8903962 00:00:00.6194775 00:00:00.6574362
7 00:00:00.8390505 00:00:00.8908841 00:00:00.6246286 00:00:00.6629505
8 00:00:00.8427880 00:00:00.8923011 00:00:00.6333484 00:00:00.6649371
9 00:00:00.8387939 00:00:00.8956879 00:00:00.6199796 00:00:00.6633562
10 00:00:00.8360664 00:00:00.8886074 00:00:00.6225067 00:00:00.6690005
11 00:00:00.8393986 00:00:00.8895964 00:00:00.6239060 00:00:00.6649108
12 00:00:00.8374107 00:00:00.8884744 00:00:00.6212659 00:00:00.6676432
13 00:00:00.8506487 00:00:00.8957254 00:00:00.6207370 00:00:00.6694316
14 00:00:00.8369340 00:00:00.8871961 00:00:00.6217399 00:00:00.6720364
15 00:00:00.8399927 00:00:00.8890604 00:00:00.6241068 00:00:00.6643618
16 00:00:00.8368528 00:00:00.8871635 00:00:00.6233056 00:00:00.6715905
17 00:00:00.8427014 00:00:00.8894616 00:00:00.6192097 00:00:00.6635785
18 00:00:00.8406117 00:00:00.8884087 00:00:00.6261769 00:00:00.6749089
19 00:00:00.8408545 00:00:00.8889903 00:00:00.6174124 00:00:00.6663618
20 00:00:00.8375089 00:00:00.8912862 00:00:00.6175829 00:00:00.6629983
Похоже, считать индекс результата когда результат найден - значительно лучше чем res_ind += 1 на каждой итерации))
Однако, по моему у меня где то ошибка. Первые 2 результата:
RAlex
аа Да Нет
1 00:00:01.9446194 00:00:01.8666370
Должны быть одинаковые, потому что входные данные те же. Вот только сколько раз я не провожу тест - первое число всё время значительно больше.
P.S. Возможно, дело в JIT-компиляции. Сейчас попробую исправив это…
P.P.S. Нет, даже с этим в начале, перед тестами:
foreach var res in s.IndicesOf0('ааа',true) do ;
foreach var res in s.IndicesOf0('абв',true) do ;
foreach var res in s.IndicesOf1('ааа',true) do ;
foreach var res in s.IndicesOf1('абв',true) do ;
Тесты с val1 оказываются значительно медленнее тестов с val2, при том что val1=val2 на первой итерации.
В общем, добавил это в цикл - теперь этот эффект менее заметен.
Ну и это всё равно влияет только на первую строчку:
program prog;
{$region RAlex 0}
function PrefixFunction0(s: string): array of integer;
// возвращает массив граней для строки-аргумента
begin
var n := s.Length;
Result := ArrFill(n + 1, 0);
for var i := 1 to n - 1 do
begin
var temp := Result[i];
while (temp > 0) and (s[i + 1] <> s[temp + 1]) do
temp := Result[temp];
Result[i + 1] := s[i + 1] = s[temp + 1] ? temp + 1 : 0
end
end;
/// Возвращает массив индексов вхождений подстроки в основную строку
///Параметр overlay определяет, разрешены ли перекрытия вхождений подстрок
function IndicesOf0(Self, SubS: string; overlay: boolean := False): array of integer; extensionmethod;
// Реализует КМП-алгоритм.
// Возвращает массив начальных позиций вхождений подстроки P в строку
// Параметр overlay определяет, разрешены ли перекрытия положений подстрок.
begin
var L := new List<integer>;
var (n, m) := (Self.Length, SubS.Length);
var border := PrefixFunction0(SubS);
var temp := 0;
for var i := 1 to n do
begin
while (temp > 0) and (SubS[temp + 1] <> Self[i]) do
temp := border[temp];
if SubS[temp + 1] = Self[i] then
temp += 1;
if temp = m then
begin
var pos := i - m + 1;
if overlay or (L.Count = 0) or (pos >= L[L.Count - 1] + m) then
L.Add(pos);
temp := border[m]
end;
end;
Result := L.Select(i -> i - 1).ToArray
end;
{$endregion RAlex 0}
{$region Sun Serega 1}
///Возвращает массив индексов вхождений подстроки в основную строку
///Использует алгоритм КМП
///Параметр allow_overlap определяет, разрешены ли перекрытия вхождений подстрок
function IndicesOf1(self, value: string; allow_overlap: boolean): List<integer>; extensionmethod;
begin
{$region prefix inds}
var val_inds := new integer[value.Length];
// val_inds[0] никогда не заполняется и остаётся нулём
// Примеры заполнения:
// value : abcab
// знач. i : 01234
// val_inds: 0012
// value : aabaabaaa
// знач. i : 012345678
// val_inds: 10123452
var prev_val_ind := 0;
for var i := 1 to value.Length-1 do
begin
while true do
begin
if value[prev_val_ind + 1] = value[i + 1] then
begin
prev_val_ind += 1;
break;
end;
if prev_val_ind=0 then break;
prev_val_ind := val_inds[prev_val_ind-1];
end;
val_inds[i] := prev_val_ind;
end;
{$endregion prefix inds}
{$region Result}
prev_val_ind := 0;
var res_l := value.Length;
var res := new List<integer>;
for var i := 1 to self.Length do
begin
while true do
begin
if value[prev_val_ind + 1] = self[i] then
begin
prev_val_ind += 1;
if prev_val_ind=res_l then
begin
res += i-res_l;
prev_val_ind := allow_overlap ? val_inds[prev_val_ind-1] : 0;
end;
break;
end;
if prev_val_ind=0 then break;
prev_val_ind := val_inds[prev_val_ind-1];
end;
end;
Result := res;
{$endregion Result}
end;
{$endregion Sun Serega 1}
procedure Otp(name: object; params ress: array of object);
begin
name.ToString.PadRight(2).Print;
foreach var res in ress do
res.ToString.PadRight(20).Print;
Println;
end;
begin
var lc1 := 100;
var lc2 := 10;
Randomize(0);
var s := new string(ArrRandom(100000, integer('а'),integer('д')).ConvertAll(i->char(i)));
Otp('','RAlex','','Sun Serega','');
Otp('аа','Да','Нет','Да','Нет');
for var l := 1 to 20 do
begin
var val1 := new string(ArrFill(l, 'а')); // строка из одинаковых символов
var val2 := new string(ArrGen(l, i->char(integer('а')+i))); // строка из всех разных символов
foreach var res in s.IndicesOf0(val1,true) do ;
foreach var res in s.IndicesOf0(val2,true) do ;
foreach var res in s.IndicesOf1(val1,true) do ;
foreach var res in s.IndicesOf1(val2,true) do ;
var sw01 := new System.Diagnostics.Stopwatch;
var sw02 := new System.Diagnostics.Stopwatch;
var sw11 := new System.Diagnostics.Stopwatch;
var sw12 := new System.Diagnostics.Stopwatch;
for var i := 1 to lc1 do
begin
sw01.Start;
loop lc2 do foreach var res in s.IndicesOf0(val1, true) do ;
sw01.Stop;
sw02.Start;
loop lc2 do foreach var res in s.IndicesOf0(val2, true) do ;
sw02.Stop;
sw11.Start;
loop lc2 do foreach var res in s.IndicesOf1(val1, true) do ;
sw11.Stop;
sw12.Start;
loop lc2 do foreach var res in s.IndicesOf1(val2, true) do ;
sw12.Stop;
System.Console.Title := (i/lc1).ToString('P');
end;
Otp(l, sw01.Elapsed,sw02.Elapsed, sw11.Elapsed,sw12.Elapsed);
end;
Readln;
end.
RAlex Sun Serega
аа Да Нет Да Нет
1 00:00:02.1613328 00:00:02.1226676 00:00:01.2343959 00:00:01.2539556
2 00:00:01.1056546 00:00:01.1317227 00:00:00.7495506 00:00:00.7937824
3 00:00:00.9389310 00:00:01.0996203 00:00:00.6746335 00:00:00.7479461
4 00:00:00.9698502 00:00:00.9317670 00:00:00.6657472 00:00:00.7220512
5 00:00:00.8824940 00:00:01.0151487 00:00:00.6589880 00:00:00.7082633
6 00:00:00.8835938 00:00:01.0484990 00:00:00.6887829 00:00:00.7360015
7 00:00:00.8897178 00:00:00.9752191 00:00:00.7362631 00:00:00.7335173
8 00:00:00.9221126 00:00:01.0302711 00:00:00.7273062 00:00:00.7653563
9 00:00:00.8952018 00:00:00.9611237 00:00:00.6610599 00:00:00.7861346
10 00:00:00.9805772 00:00:00.9629134 00:00:00.6575169 00:00:00.7166497
11 00:00:00.8648718 00:00:00.9530304 00:00:00.6574951 00:00:00.7063142
12 00:00:00.8405118 00:00:00.8923351 00:00:00.6364620 00:00:00.6900514
13 00:00:00.8277424 00:00:00.8820249 00:00:00.6587564 00:00:00.6810963
14 00:00:00.8347925 00:00:00.8828806 00:00:00.6300331 00:00:00.6767473
15 00:00:00.8529276 00:00:00.9066059 00:00:00.6505163 00:00:00.6831164
16 00:00:00.8747458 00:00:00.9555723 00:00:00.6497714 00:00:00.7148019
17 00:00:00.8648588 00:00:00.8949987 00:00:00.6362897 00:00:00.6815480
18 00:00:00.9075164 00:00:00.9575830 00:00:00.6498875 00:00:00.7739918
19 00:00:00.9624533 00:00:00.9265848 00:00:00.6731339 00:00:00.7078776
20 00:00:00.9940469 00:00:00.9388618 00:00:00.6454581 00:00:00.7195870
Кстати, сравнивать имеет смысл только значения справа и слева друг от друга, потому что они тестировались одновременно.
Как можете видеть - в некоторых строчках времени тратиться неожиданно дольше предыдущих - это значит что у меня комп был ещё чем то занят в этот момент.
Но что можно сравнивать - так это, к примеру, то что с увеличением длины искомой строки становиться важнее, одинаковые ли в ней символы.
Но и оттуда тоже - нельзя их не учитывать. Там тесты на огромных строках, возможно, каких-то вычурных даже, но это олимпиадные тесты и не надо их игнорировать: они сделаны специально, чтобы максимально загнать в тупик программу, т.е. это все же критерии стрессоустойчивости. Вы сами знаете, чего стоит отдельные задания там загнать в рамки.
Это видано и не раз. Первое вхождение искать всегда быстрее, чем все. Проверял и я, и @Admin, когда только обсуждалось, делать ли IndexOf вообще, и если делать, то как.
Например, когда надо обработать не все вхождения, а проанализировать отдельные.
А это-то тут причем? Речь не об изменении средств контроля время выполнении, а об изменении в реализации алгоритма.
Вот только вы сами сказали, в расчёт времени берётся и запуск программы, и JIT-компиляция. Это - не относится к алгоритму. И, что важнее - это не стабильные результаты.
Да, разумеется. Но .IndexOf это не регулярки и даже не КМП. Это обычный поиск подстроки перебором всех позиций.
А регулярки это вот:
begin
(new Regex('***')).Match(ReadString).Index
end.
И они никогда не могут быть даже сравнимыми по скорости с .IndexOf, потому что алгоритм на много сложнее.
А зачем для этого массив? Даже если сравнивать рядом стоящие индексы - это что то типа .Pariwise . Так а для какого типа анализа надо прям все индексы одновременно в памяти держать?
К тому, что стопвочем не только можно всё то же замерить, но ещё и точнее и без дополнительных онлайн ресурсов, у которых не узнать наверняка что под копотом.
Да, я писал, что пользователю неинтересно, как быстро выполняется какой-то кусок внутри программы. И это реально так. А результаты достаточно стабильны, с точностью до 0.03с.
Это была описка, мы проверяли IndicesOf.
Не обязательно все. Например, если надо сделать в строке замену не каждого вхождения. А только такого, которое идет после/перед каким-либо контекстом. Либо, обработать вхождения кроме первого. Или кроме первого и последнего. И т.п. Задачи самые разные бывают.
Ну так а если не все - массив не нужен.
И для обоих задач что вы назвали - больше 1 индекса одновременно хранить в памяти не нужно.
 Институт математики, механики и компьютерных наук ЮФУ, 2005–2021
Институт математики, механики и компьютерных наук ЮФУ, 2005–2021