Нет, файл как раз бинарный (для записи используется file of T, который использует BinaryWriter и BinaryReader). Вот только я не понял вас, на что это влияет)).
Нет, Вы меня не правильно поняли. Я имел ввиду, что файл имеет простую структуру. Сериализация позволяет сохранить состояние объекта, т. е. объект полностью. Если бы строка сохранялась через сериализацию, данные о её длине записывались бы в файл.
1 лайк
В файле не сохраняется
Файл не текстовый а типизированный
А как тогда из файла считывает длину строки? Я же говорю, длину короткой строки не передаёт никуда, в этом и странность. Её, в байтах, вытягивает из файла. Хотя туда ничего и не сохранялось, как вы и говорите. Скорее всего, значит, я где то пропустил передачу это длинны. Вот где и куда эта длинна строки передаётся? Кроме всего прочего, каждое поле записи имеющее тип короткой строки сохраняется как просто строка. То есть внутри поля длинна не хранится. Я вообще не нашёл где они хранится в оперативке, до сохранения.
Никак. Так же как и случае если мы из файла целых будем считывать вещественные - что-то пойдёт не так.
Не путайте это с сериализацией
type
r1=record
s:string[5];
end;
begin
var f:file of r1;
f.Write(new r1);
end.
При чтении вызывается:
-
!!0/*valuetype Program1.r1*/ PABCExtensions.PABCExtensions::Read<valuetype Program1.r1>(class PABCSystem.TypedFile). Оно сразу передаёт управление в: -
object PABCSystem.PABCSystem::TypedFileRead(class PABCSystem.TypedFile). Там производится несколько проверок с вызовом исключений, и управление передаётся в: -
object PABCSystem_implementation______.PABCSystem_implementation______::AbstractBinaryFileReadT(class PABCSystem.AbstractBinaryFile, class [mscorlib]System.Type, int32&, bool). Оно, в зависимости от типаTизfile of Tвызывает соответствующие методы для чтения. У нас тут запись, поэтому вызывается следующий участок:
else if (t.IsValueType)
{
object instance = Activator.CreateInstance(t);
FieldInfo[] fields = t.GetFields();
int num = fields.Length - 1;
int index = 0;
if (index <= num)
{
while (true)
{
if (!fields[index].IsStatic)
fields[index].SetValue(instance, PABCSystem_implementation______.PABCSystem_implementation______.AbstractBinaryFileReadT(f, fields[index].FieldType, ref ind, in_arr));
if (index < num)
++index;
else
break;
}
}
obj1 = instance;
}
Поле у нас всего 1. Для него ещё раз вызывается:
-
object PABCSystem_implementation______.PABCSystem_implementation______::AbstractBinaryFileReadT(class PABCSystem.AbstractBinaryFile, class [mscorlib]System.Type, int32&, bool). Только в этот раз мы передалиstringкак тип который надо считать, потому что вr1полеsобъявлено как обычноеstring, неstring[5]. В данном случае вызывается следующий код:
else if (t == typeof (string))
{
obj1 = (object) f.br.ReadString();
if (((!(f is TypedFile) ? 0 : 1 & ((f as TypedFile).offsets != null ? 1 : 0)) == 0 ? 0 : 1 & ((f as TypedFile).offsets.Length > 0 ? 1 : 0)) != 0)
f.br.BaseStream.Seek((long) ((f as TypedFile).offsets[ind] - (obj1 as string).Length), SeekOrigin.Current);
if (!in_arr)
PABCSystem.PABCSystem.Inc(ref ind);
}
Самое первое что вызывается - это:
-
f.br.ReadString(), то естьinstance string [mscorlib]System.IO.BinaryReader::ReadString(). Теперь мы в кодах стандартных библиотек .Net . Эта функция выглядит так:
public virtual String ReadString() {
Contract.Ensures(Contract.Result<String>() != null);
if (m_stream == null)
__Error.FileNotOpen();
int currPos = 0;
int n;
int stringLength;
int readLength;
int charsRead;
// Length of the string in bytes, not chars
stringLength = Read7BitEncodedInt();
if (stringLength<0) {
throw new IOException(Environment.GetResourceString("IO.IO_InvalidStringLen_Len", stringLength));
}
if (stringLength==0) {
return String.Empty;
}
if (m_charBytes==null) {
m_charBytes = new byte[MaxCharBytesSize];
}
if (m_charBuffer == null) {
m_charBuffer = new char[m_maxCharsSize];
}
StringBuilder sb = null;
do
{
readLength = ((stringLength - currPos)>MaxCharBytesSize)?MaxCharBytesSize:(stringLength - currPos);
n = m_stream.Read(m_charBytes, 0, readLength);
if (n==0) {
__Error.EndOfFile();
}
charsRead = m_decoder.GetChars(m_charBytes, 0, n, m_charBuffer, 0);
if (currPos == 0 && n == stringLength)
return new String(m_charBuffer, 0, charsRead);
if (sb == null)
sb = StringBuilderCache.Acquire(stringLength); // Actual string length in chars may be smaller.
sb.Append(m_charBuffer, 0, charsRead);
currPos +=n;
} while (currPos<stringLength);
return StringBuilderCache.GetStringAndRelease(sb);
}
Первое что вызывается (кроме разных проверок) это:
-
stringLength = Read7BitEncodedInt();, то естьinstance int32 System.IO.BinaryReader::Read7BitEncodedInt(). Его код я уже недавно заливал сюда, но залью ещё раз:
internal protected int Read7BitEncodedInt() {
// Read out an Int32 7 bits at a time. The high bit
// of the byte when on means to continue reading more bytes.
int count = 0;
int shift = 0;
byte b;
do {
// Check for a corrupted stream. Read a max of 5 bytes.
// In a future version, add a DataFormatException.
if (shift == 5 * 7) // 5 bytes max per Int32, shift += 7
throw new FormatException(Environment.GetResourceString("Format_Bad7BitInt32"));
// ReadByte handles end of stream cases for us.
b = ReadByte();
count |= (b & 0x7F) << shift;
shift += 7;
} while ((b & 0x80) != 0);
return count;
}
И тут, как видите, длине строки (в байтах) присваивается число считанное из файла.
Я прошёл по списку вызовов уже несколько раз, но всё ещё не вижу в чём тут дело, где пропущена передача длинна короткой строки? Если вы говорите что в файл не записывается длинна, где тогда у меня ошибка, в списке вызовов выше?
Я не знаю. А что, что-то не так работает?
Ещё раз, тут длинна строки считывается из файла. А вы говорите что не считывается. А я пытаюсь понять, как устроены типизированные файлы. Как раз из за того что они как шкатулка пандоры, потому что непонятно когда что то выскочит - баг ли это, я боялся их всегда использовать. Вот сейчас пытаюсь разобраться, но - оно как на тёмной магии работает.
Вы влезли в самую грязную возможность в типизированных файлах - файлы коротких строк. Короткие строки устарели.
Длина строки не записывается в файл.
Код проекта на страницах форума я объяснить не смогу по двум причинам: он писался лет 8 назад и не мной.
Я попробую.
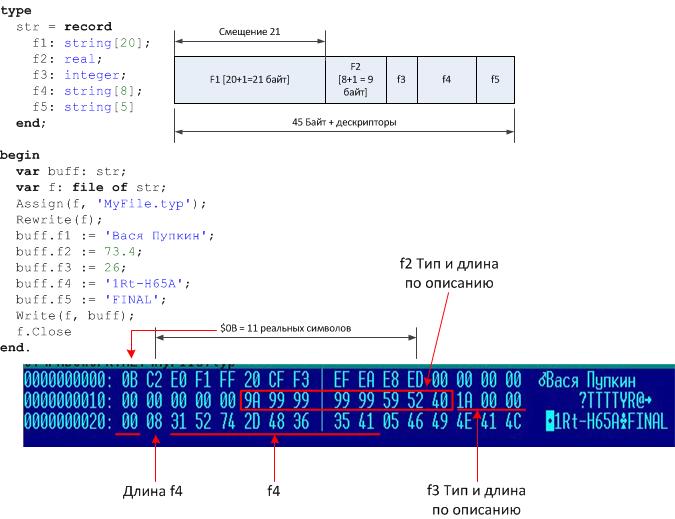
type
str = record
f1: string[20];
f2: real;
f3: integer;
f4: string[8];
f5: string[5]
end;
begin
var buff: str;
var f: file of str;
Assign(f, 'MyFile.typ');
Rewrite(f);
buff.f1 := 'Вася Пупкин';
buff.f2 := 73.4;
buff.f3 := 26;
buff.f4 := '1Rt-H65A';
buff.f5 := 'FINAL';
Write(f, buff);
f.Close
end.
45 байт длина буфера, плюс три символьных поля - это три дескриптора фактической длины. Файл будет содержать записи длиной 48 байт.
Короткие строки устарели, а другие в типизированный файл записать невозможно. Убираем типизированные файлы, которые одна из лучших идей в Паскале?
“Трус не играет в хоккей!”. Нет в них ничего сакрального, работают, как часы. Однобайтный дескриптор фактической длины строки - как раз причина ограничения ее длины 255 байт.
1 лайк
Подождите, а почему на f2 выделяется 9 байт, если это real? Откуда берётся +1 там?
И, значит, длинна строки таки записывается в файл, но на это тратится только 1 байт?
На файле видно, что на f2 8 байт выделяется, это я скопировал и не все поправил. Дескрипторы - только у строк. Записывается не длина поля, а фактическое число байт в строке, чтобы нули бинарные не читать потом.
Запись из файла, если читаем потом - она как батон колбасы. Нарезается на ломтики по описанию. Нет описания структуры - запись не расшифровать. И лишь потом каждый ломтик интерпретируется в соответствии с типом.
1 лайк
А вот тут опять странно. Если объявить длину строки >127 (к примеру, 128) - под длину выделяет 2 байта (ибо 7-битная кодировка). И максимум под длину может выделить 5 байт, таким образом описать можно строку любой длинны (от которой комп не загнётся, в оперативке держать). Так что это не объясняет ограничение в длинны в 255. Это вообще не объясняет, зачем нужно это ограничение. Раз длину строки таки сохраняет в файл, и её определяет на рантайме.
Я не знаю, как именно реализовано тут и тестировать разные варианты мне неинтересно совершенно. Скаутские годы уже как бы прошли, наигрался. Я Вам приводил пример, как это было реализовано у Вирта и в турбопаскалях. Т.е. как было задумано и почему именно так.
1 лайк
Третий раз - не длину строки, которая максимально возможной описана, а фактическую. Для строк переменной длины длина записи гулять будет. В типизированном файле НЕТ разделителей записи, он как бинарный - сколько хочу, столько и читаю за раз. Так что не зная реальной длины на переменных строках, Вы читать будете сразу весь файл? Или как?
Ну и что, в файле записана длинна строки, а значит - знаем когда остановится, чтоб весь файл не читать. И, это встроенный функционал бинари риадера. Паскаль им пользуется, но потом ещё изменяет положение в потоке (к примеру если макс 6, а фактическая 5 - переставит на 1 байт вперёд). Возможно, это было сделано для совместимости. Но раз строкам длинной >127 символов сохраняет длину как 2 байта - это уже не совместимо с тем что придумывал Вирт.
Вы правда не понимаете или на ночь глядя повеселиться решили?
Какая длина строки известна? фактическая? Но запись файла - это же не единственное символьное поле, так сколько байт читать будем? Не про запись речь, про чтение. Или Вы читать по 1 байту предлагаете за операцию и пытаться угадать, что там и как? Вы понимаете, что получается файл, содержащий что-то, у которого записи не разделяются? Какого размера порции читать из него?
Есть файл. Как узнать, сколько из него байт читать, если о нем ничего не известно - ни сколько там записей, ни какой длины каждая из них? Только побайтное чтение и попытка динамически определить конец очередной записи. Но побайтное чтение крайне медленно, следовательно, совершенно неэффективно.
Это именно то что сейчас происходить. Ну не по 1 байту, но по 1-8 для большинства полей. И для строки - длину всё равно определяет динамически. Потом ей всё тело читает разом, одним блоком, но длину этого блока всё равно определяет только прочитав несколько первых байт, в которых описана длина.
Основная проблема с тем чтоб записи с короткими читать по блоку на запись - это то что string[5] это не value-тип. string[5] заменяется на string после компиляции. И в итоге строка не хранится как поле записи, в записи хранится только ссылка на эту строку. А как известно, записи с ссылочными полями 1 блоком точно никак не прочитаешь.
Ну вот к примеру:
r1=record
s:string;
end;
var a,b:r1;
a.s := 'abc';
b.s := 'abcde';
f.write(a);
f.write(b);
В файле это будет записано как:
$3, a, b, c, $5, a, b, c, d, e
Но сейчас (если тип поля s заменить на string[5]) - их записывает так:
$3, a, b, c, $0, $0, $5, a, b, c, d, e
Вот я и говорю, это можно было бы приписать к “ради совместимости”, но если длинна строки 128 - её сохраняет как
$80, $01
а не
$80
Потому что бинари риадер и врайтер используют 7-битную кодировку. И в данном случае старший бит первого байта для них значит не 128, а надо прочитать ещё 1 байт. И, значит, нет ни совместимости, ни всех возможностей бинари риадера и врайтера.
Да и хотел бы уточнить:
- Я никогда над ни над кем не подшучивал. Тем более я не буду этого делать где то вроде этого форума;
- Хоть вы и сказали что не интересуетесь и не хотите лезть в это, но:
- это помогает мне лучше сформулировать мысль, насчёт того что именно мне кажется странным. И вы лучше меня знаете как вирт задумывал эту запись, если бы вы не написали - я бы не подумал что это может быть ради совместимости.
Задумано, что она читается именно целиком, потому что по типу можно определить полную длину записи.
Запись читается целиком в буфер, а потом разбирается по полям уже из оперативной памяти. Классически задумано именно так и этому есть простое объяснение. Когда Вирт это дело придумывал, основными внешними носителем были магнитная лента и магнитный диск. Читать с тех медленных носителей побайтно было нереально. Поэтому читали блоками фиксированной длины.
Для чтения текстовых файлов контроллеры внешних устройств имели собственную “микропрограмму”, которая организовывала буфер некоторой разумной длины, читала туда данные и выискивала $0D0A.
1 лайк
 Институт математики, механики и компьютерных наук ЮФУ, 2005–2021
Институт математики, механики и компьютерных наук ЮФУ, 2005–2021