А что если сделать его не одним байтом а четырьмя (Int32) и перестать мучаться с короткими строками? Int32 может определить максимальную длину обычной строки. Зачем такой геморрой с 255 байтами?
Допустим, есть такая структура:
Type my = Record
Public a: Int32;
Public b: String;
Public c: Byte;
End;
Сначала в файл сохранено 4 байта от поля a, затем - ещё 4 байта - длина строки, а уже потом - сами символы. Ну и в конце один байт поля c.
Файлы такого типа создать нельзя
Посмотрите, что я предложил выше по этому поводу.
Если сильно захотеть - как файлы типа Text, а не типа r1.Но вот читать их придется тоже как тип Text. А это и так имеется. Все эти идеи со строками неопределенной длины в типизированном файле - они от зашоренности сознания низкоуровневыми играми в указатели и ввод/вывод по отдельным байтикам. Болезнь С/С++. Похоже, что @Sun_Serega все же проникся пониманием работы Паскаля с файлами и прекратил тщетные рационализаторские потуги 
Пожалуйста, не отсылайте куда-то
Я же Вам пытаюсь помочь…
В серьёзном проекте я всё равно буду использовать System.IO)) Но в проекте на 200 строк - этот тип может пригодится.
Сейчас строка и так может всю свою длину сохранить, её ограничивает на 255 только паскаль. Если сейчас убрать это ограничение (ну и убрать костыльное исправление позиции в файле) - всё будет работать. Хотя, конечно, тогда нет совместимости со старыми версиями. Сейчас подробнее в следующем ответе админу опишу…
1 лайк
Ну так понятное дело  Причём не просто Паскаль, а Турбо Паскаль
Причём не просто Паскаль, а Турбо Паскаль 
Я именно это и предлагаю. Надо всего лишь Byte на Int32 заменить и готово.
@Admin, смотрите, я до разобрался с тем как работают типизированные файлы. И, сейчас, у них сломана совместимость со старыми паскалями.
Я предлагаю 2 варианта:
-
Окончательно доламать совместимость, но зато использовать все возможности .Net . Это позволит записывать в файл всё, и динамические массивы, и любые строки. Для этого почти ничего не надо исправлять, 10-15 строчек макс.
-
Починить совместимость со старыми паскалями. Сейчас короткие строки не правильно сохраняются, не в том формате. Вот смотрите, программа на Турбо паскале (специально скачал):
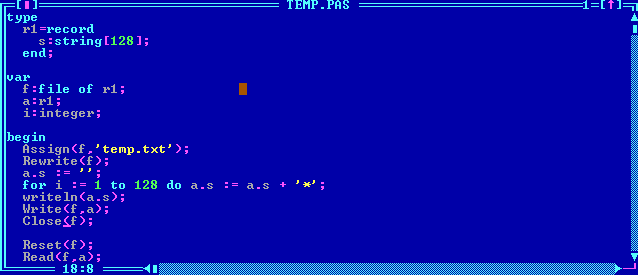
Эта программа создаёт следующий файл:
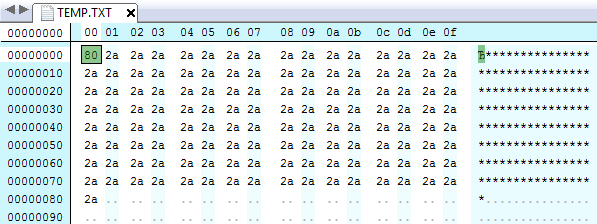
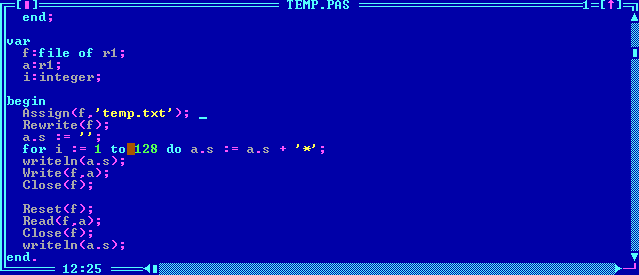
Как видите, под длину строки выделило всего 1 байт, и записало в него число 128. Теперь напишем то же самое на PascalABC.Net:
type
r1=record
s:string[128];
end;
begin
var f:file of r1;
Rewrite(f,'temp.txt');
var a:r1;
a.s := '*'*128;
writeln(a.s);
f.Write(a);
f.Close;
Reset(f);
a := f.Read;
f.Close;
writeln(a.s);
end.
Эта программа создаёт следующий файл:
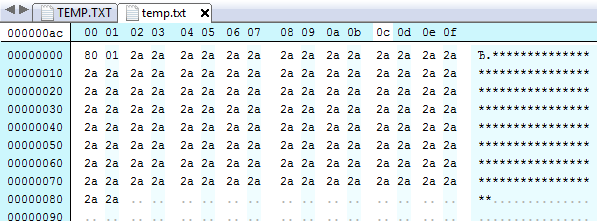
И тут уже на длину строки выделило 2 байта! А значит это не совместимо с старыми паскалями.
Более того, так как это сейчас реализовано - всё преимущество типизированных фалов пропадает: В старых паскалях всё сохранялось/загружалось 1 блоком. А сейчас - сохраняется/загружается по 1 полю.
Если уже сохранять по 1 полю - то нет смысла запрещать динамические типы. Их запрет был только ради того чтоб можно было 1 блоком, всё вместе сохранить. А если чинить совместимость - надо переделать так чтоб всё сохранялось 1 блоком.
Ну и так же, как я и сказал, есть вариант - оставить оба способа, для file of T сделать совместимым со старыми паскалями, а тому другому способу дать возможность записывать динамические типы.
Я разобрался как типизированные файлы устроены (там довольно просто, меня лишь сбило ваше “длина строки не сохраняется файл”) и могу сделать большую часть, но чтоб заставить короткие строки работать (не через костыли) - надо будет добавить их как отдельный тип в язык, а не костыльная надстройка над string.
Вы так придете к струтуре записи файла, которая была еще в IBM System\360. Да и еще в bBASE фалы базы данных примерно так же были устроены. В начале писался управляющий блок (header), описывающий структуру данных (длина поля, тип поля), а затем шли непосредственно записи. Но даже там записи всегда были фиксированной длины, чтобы не читать по одному байтику.
Я предложил этот вариант только потому, что для него почти ничего менять не придётся. Большая часть кода уже есть, достаточно убрать несколько ограничений и исправить пару вещей, которые будут работать не так (но там всё элементарно).
Знаете, у Вас есть редкая возможность написать программу, чтобы прочитать файл, который создан, в какой-то степени, моделируя типизированный Вот этот файл: MyFile.bin (2,9 КБ)
А вот программа, которая его создала.
type
t1 = record
f1: real;
f2: integer;
f3: string;
f4: integer;
f5: string
end;
begin
var f: file;
var b: t1;
Assign(f, 'MyFile.bin');
Rewrite(f);
loop Random(3, 5) do
begin
b.f1 := Random;
b.f2 := Random(1, 500);
var s := String('');
loop b.f2 do
s += ChrAnsi(Random(32, 255));
b.f3 := s;
b.f4 := Random(1, 500);
s := String('');
loop b.f4 do
s += ChrAnsi(Random(32, 255));
b.f5 := s;
Write(f, b)
end;
f.Close
end.
Поля f2 и f4 - дескрипторы строк f3 и f5.
Я вас не совсем понял.
- Дескрипторы должны иметь длину в 1 байт а не 4.
- В вашей программе длину строки сохраняет в файл 2 раза. Ваш дескриптор, 4 байта в 8-битной кодировке, и ещё раз в 7-битной кодировке, которую используется
System.IO.BinaryWriter.
Всё новое - хорошо забытое старое. Ну а если серьёзно - эта структура очень динамична. То что она сложная(хотя ничего сложного там нет. Посмотрите на Google Protobuf File и поймёте о чём я) ещё не значит, что она плохая.
Никто ведь и не предлагает по байту читать  Читаем 4 байта - размер блока, а затем сам блок.
Читаем 4 байта - размер блока, а затем сам блок.
Но тогда макс. длина - 255. Надо переходить на 4, как я предлагаю. Тогда - много больше.
Можете примерно рассказать, что делает эта программа?
Это сделано для совместимости со старым Паскалем. Это очень старый код, неиспользуемый, его никто улучшать не будет.
А может пора наплевать на совместимость “в лоб”? Совместимость уже и так нарушена, но никому это проблем не доставило. Если вопрос появился, значит - нужно.
Вы посмотрите внимательнее. Два раза лишь потому, что две строки сохраняется, у каждой свой дескриптор. 4 байта взято для примера: Вы как хотите сохранять в 1 байте длину строки больше 255 байт?
Могу, конечно. Случайным образом генерирует будущее число записей в файле. Затем заполняет случайными числами буферную переменную указанной структуры. В частности, генерирует случайные длины строк, а затем сами строки из случайного набора символов.
Проблема в том, что для того, чтобы из такого файла получить “назад” записанные данные, его нужно специальным образом читать, динамически получая размер следующей порции считываемых данных. При этом невозможно оперативно узнать, сколько записей в файле, пока его весь не прочитаешь и не расшифруешь.
Если это реализовать для типизированного файла, как в нем выполнять
function Seek<T>(Self: file of T; n: int64): file of T;
Устанавливает текущую позицию файлового указателя в типизированном файле
на элемент с номером n
Вы представляете, сколько времени нужно будет на работу с таким файлом?
Понял, уже занимаюсь этим. А Вы сможете поверить правильность?
 Институт математики, механики и компьютерных наук ЮФУ, 2005–2021
Институт математики, механики и компьютерных наук ЮФУ, 2005–2021